Details
| Project Framework | Horizon 2020 Marie Skłodowska-Curie Actions Individual Fellowship |
|---|---|
| Project Call | H2020-MSCA-IF-2016 |
| Project title | ProsoDeep : Deep understanding and modelling of the hierarchical structure of Prosody |
| Supervisor | Gérard Bailly, GIPSA-lab, Grenoble Institute of Technology, Grenoble, France |
| Researcher | Brаnislаv Gеrаzоv, FEEIT, Ss Cyril and Methodius University in Skopje, Macedonia |
| Project partners | Yi Xu, University College London, London, United Kingdom |
| Philip Garner, Idiap Research Institute, Martigny, Switzerland |
Objectives
The prime objective of the ProsoDeep project is to gain a deeper understanding of the language of prosody through the analysis of all the levels in the production hierarchy of prosody. In particular, it will exploit the benefits of the top-down and bottom-up approaches through their incorporation within a deep prosody model (DPM).
The DPM will facilitate the advancement of speech technologies that rely both on the synthesis of prosody, e.g. text-to-speech (TTS) systems, and its analysis, e.g. speech recognition and speech emotion recognition (SER). To reach this objective the project will draw on a variety of scientific fields, including signal processing, physiology of prosody production and biomechanics, linguistics, and machine learning, and will also be augmented with respiratory measurements.
The problem
Prosody is a multidimensional phenomenon comprising intonation, energy, and rhythm. It is the carrier of both linguistic information, e.g. sentence structure, focus and contrast, lexical stress; as well as paralinguistic information, e.g. gender, age, personality, and emotions. In recent years, prosodic research has considerably enlarged the spectrum of properties and functions. In contrast, prosodic models able to map signals to functions or vice-versa are rare: comprehensive models of rhythm and intonation have difficulties coping with this expanding dimensionality, and machine learning techniques still have difficulties with offering structuring principles.
State-of-the-art
The importance of prosody in TTS systems has been the driving force in the development of prosody models, with a special focus on intonation. Most of these models follow a bottom-up approach, i.e. from signals to functions. A number of intonation models following this approach also incorporate physiological constrains. Only a few models seek to model prosody taking a top-down function that starts with the linguistic functions themselves.
SFC
The Superposition of Functional Contours (SFC) model is a top-down approach based on the decomposition of prosodic contours into functionally relevant elementary contours [sfc]. It proposes a generative mechanism for encoding socio-communicative functions, such as syntactic structure and attitudes, through the use of prosody. The SFC has been successfully used to model different linguistic levels, including: attitudes, dependency relations of word groups, word focus, tones in Mandarin, etc. It has been used for a number of languages including: French, Galician, German and Chinese. Recently, the SFC model has been extended into the visual prosody domain through modelling facial expressions and head and gaze motion [sfc-av]. An example decomposition of an intonation contour into its functional prototypes is shown in Fig. 1.
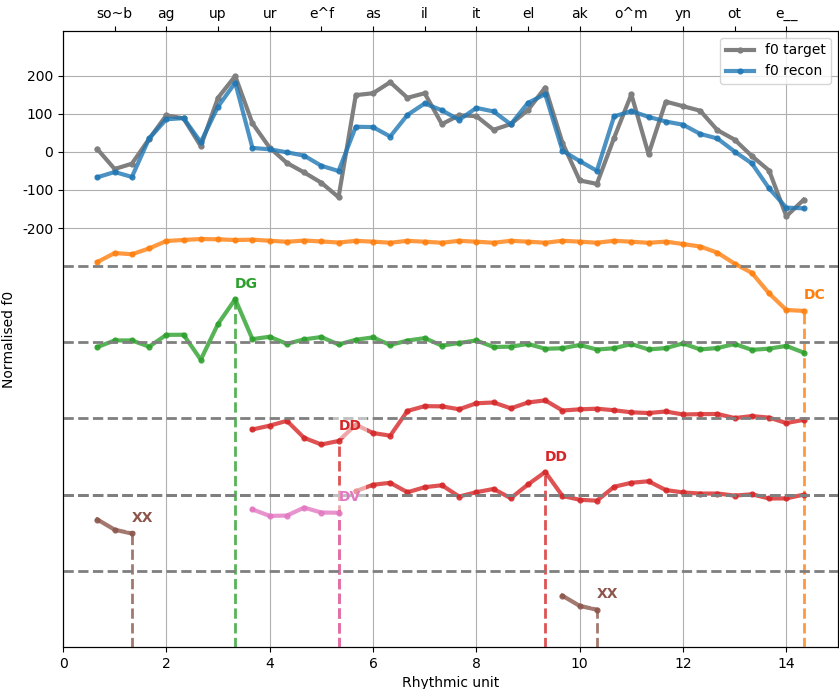
Fig. 1 — Example PySFC intonation decomposition for the French utterance: Son bagou pourrait faciliter la communauté. into constituent functional contours: declaration (DC), dependency to the left/right (DG/DD), and cliticisation (XX, DV).
More example plots and details on the SFC model are given in PySFC, which is a Python implementation of the SFC.
SFC tries to solve the many-to-many ill-posed problem of determining the shape of the function specific contours. A major limitation of the SFC is that it only extracts the average contour for each function prototype.
GCR
One representative bottom-up model with physiological constraints is the Generalized Command Response (GCR) model [gcr] that decomposes the intonation contour using \(f_0\) atoms that correspond to elementary muscle activations, as shown in Fig. 2. The parameters of the GCR model can be trained completely automatically using a matching pursuit algorithm with the perceptually relevant weighted correlation as a cost function. As it is based on the physiology of intonation production, the model is inherently speaker and language independent. This is experimentally confirmed for English, French and German. The GCR atoms were also shown to have linguistic significance when compared to ToBI events, and can be used to help extract and synthesise emphasis.
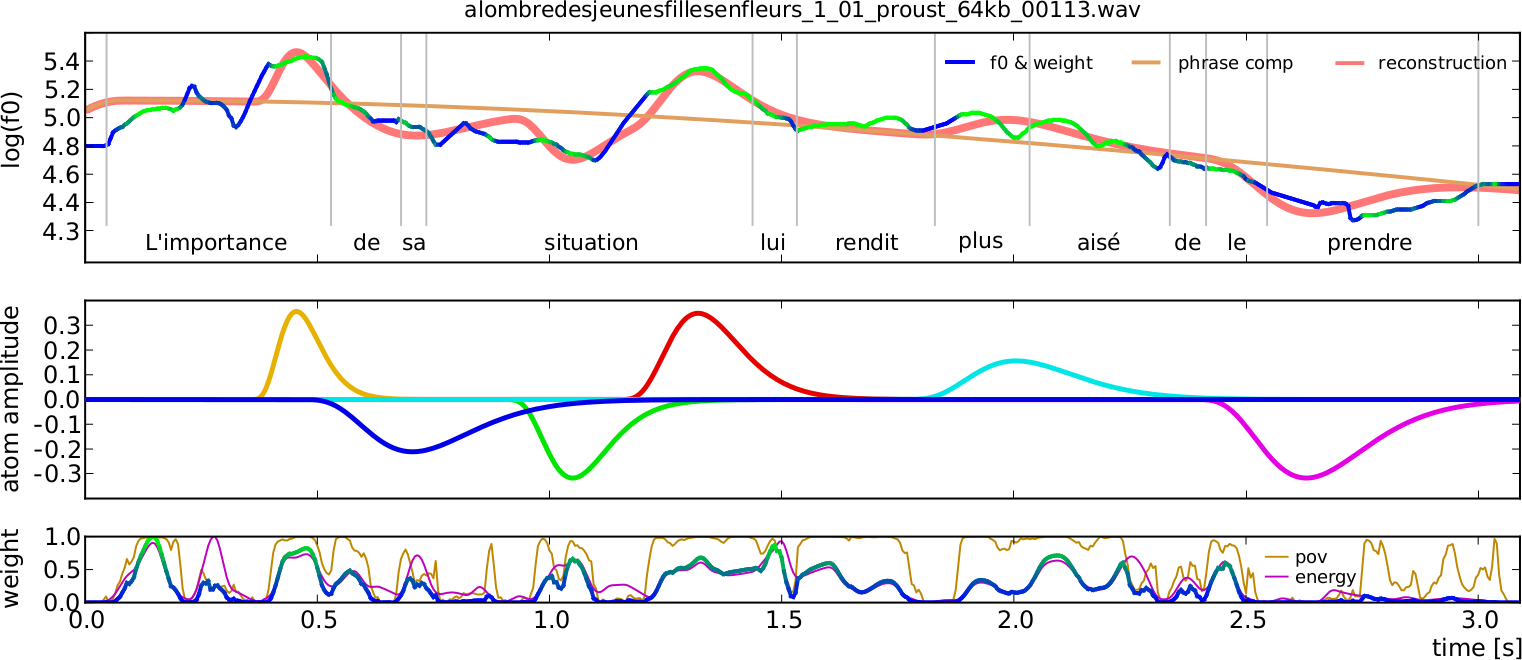
Fig. 2 — Results obtained with the WCAD algorithm for the sentence “L’importance de sa situation lui rendit plus aisé de le prendre.” by a French male speaker, showing the: original \(f_0\) colored blue to green according the probability of voicing (POV) — green is higher, extracted phrase atom and reconstructed \(f_0\) (top), extracted elementary accent atoms (middle), and the energy, the POV and the weighting function (bottom). Taken from [gcr-wcad]
The implementation of the GCR parameter extraction algorithm called Weighted Correlation based Atom Decomposition (WCAD) is free software and is available on GitHub at: https://github.com/dipteam/wcad
The main problem with the bottom-up approach is that it is difficult to establish the linguistic significance of the extracted model parameters.
Goal
The DPM will seek to merge the strengths of these two opposing paradigms. Specifically, we will expand further on the methodology developed in the SFC while incorporating GCR’s physiological constraints.