VPM
To Variational Prosody Model (VPM) is able to capture a part of the prosodic prototype variance [vpm]. Its variational CGs (VCGs) shown in Fig. 1 (all figures taken from [vpm]), use the linguistic context input to map out a prosodic latent space for each contour.
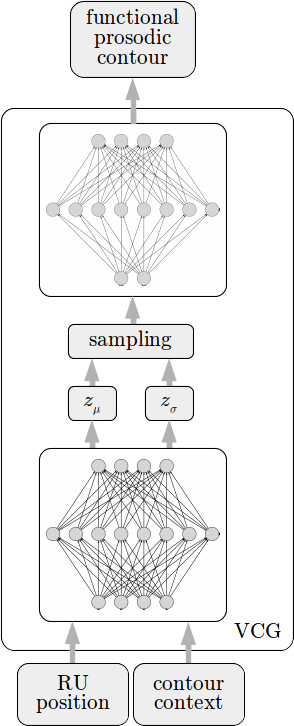
Fig. 1 — Variational contour generator introduced in the VPM that features a variational encoding mapping function context and rhythmic unit position into a prosodic latent space.
Unlike the SFC, which uses analysis-by-synthesis, the VPM integrates all the VCGs within a single network architecture shown in Fig. 2, and trains them jointly using backpropagation. This eliminates the ad hoc distribution of errors and leads to better modelling performance.
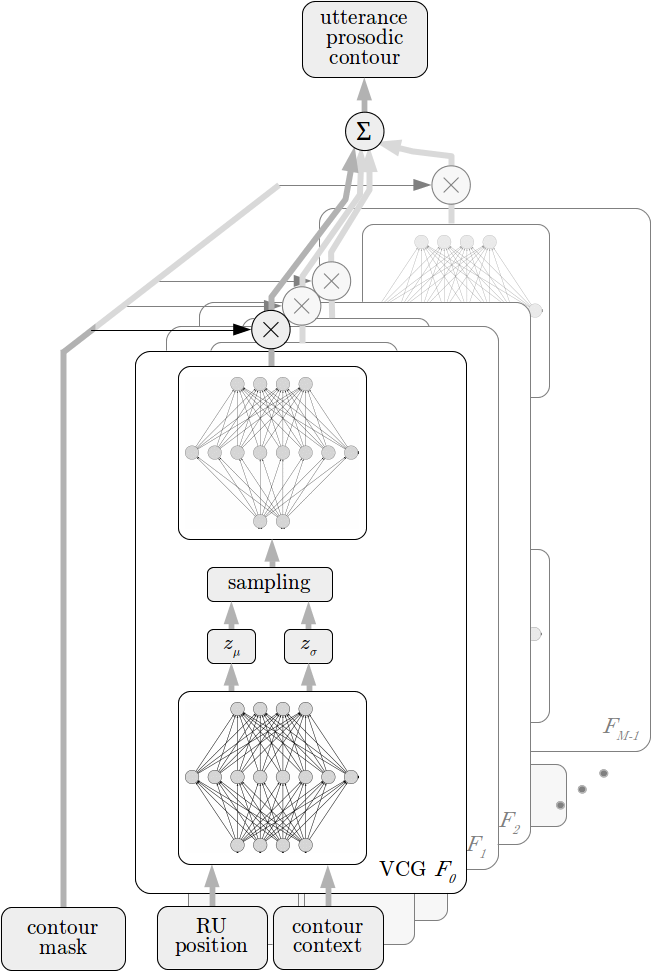
Fig. 2 — VPM architecture comprising VCGs for each function and allowing their joint training.
Prosodic latent space
The mapped two-dimensional latent space can be used to visualise the captured context-specific variation, shown in Figs. 3 and 4. Since the VCGs are still based on synthesising the contours based on rhythmic unit position input, the mapped prosodic latent space is amenable for exploration only for short contours, such as Chinese tones or clitics.
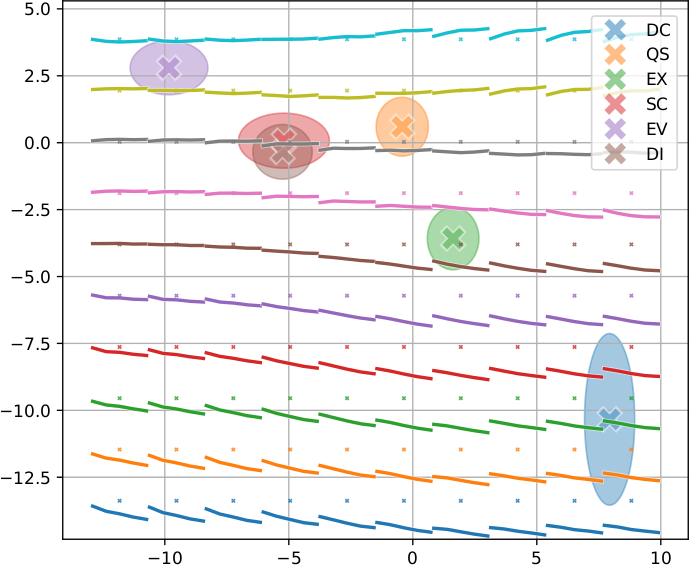
Fig. 3 — The prosodic latent space of the clitic functional contour (XX) demonstrates that a full blown contour is only generated in context of the declaration (DC) and exclamation (EX) attitudes, while it is largely diminished for the rest.
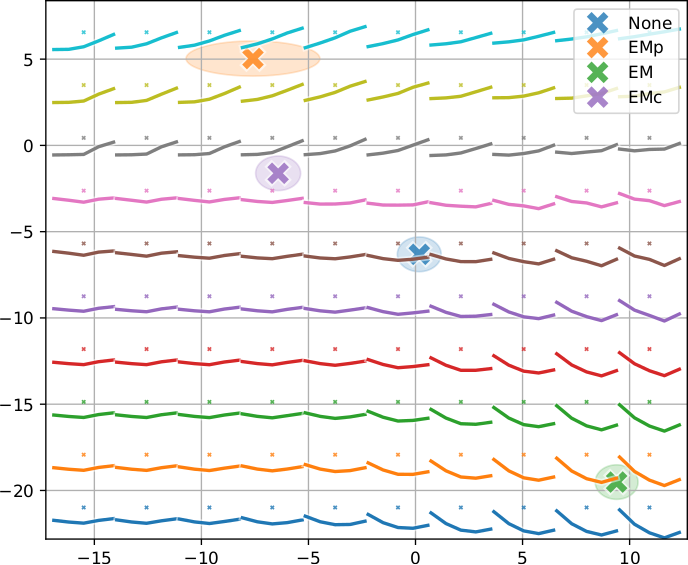
Fig. 4 — Prosodic latent space of the tone 3 functional contour in context of no-, pre-, on- and post-emphasis (None, EMp, EM, and EMc), as extracted by the VPM.